注:本文为重新发布2017-06-17所写博客,以下为正文部分。
上周我们的存储服务在某个线上项目频繁出现崩溃,花了几天的时间来查找解决该问题。在这里,将这个过程做一下记录。
加入调试信息 #
由于问题在线上发生,较难重现,首先想到的是能不能加上更多的信息,在问题出现时提供更多的解决思路。
首先,我们的代码里,在捕获到进程退出的信号比如SIGABRT、SIGSEGV、SIGILL等信号时,会打印出主线程的堆栈,用于帮助我们发现问题。
但是在崩溃的几次情况中,打印出来的信息并不足以帮助我们解决问题,因为打印的崩溃堆栈只有主线程,猜测是不是在辅助线程中发生的异常,于是采取了两个策略:
- ulimit命令打开线上一台服务器的coredump,当再次有崩溃发生时有core文件产生,能够帮助发现问题。
- 加入了一些代码,用于在崩溃的时候同时也打印出所有辅助线程的堆栈信息。
在做这两部分工作之后,再次发生崩溃的情况下,辅助线程的堆栈并无异常,core文件由于数据错乱也看不出来啥有用的信息来。
复现问题 #
由于第一步工作受挫,接下来我的思路就在考虑怎么能在开发环境下复现这个问题。
我们的存储服务在其他项目上已经上线了有一段时间了,但是并没有出现类似的问题。那么,出现问题的项目,与其他已经上线的服务有啥不同,这里也许是一个突破口。
经过咨询业务方,该业务的特点是:
- 单条数据大:有的数据可能有几KB,而之前的项目都只有几百字节。
- 读请求并发大,而其他业务是写请求远大于读请求。
由于我们的存储服务兼容memcached协议,出现问题时也是以memcached协议进行访问的,所以此时我的考虑是找一个memcached压测工具,模拟前面的数据和请求特点来做模拟压测。
最后选择的是twitter出品的工具twemperf,其特点是可以指定写入缓存的数据范围,同时还可以指定请求的频率。
有了这个工具,首先尝试了往存储中写入大量数据量分布在4KB~10KB的数据,此时没有发现服务有core的情况出现。 然后,尝试构造大量的读请求,果然出现了core情况,重试了几次,都能稳定的重现问题了。
有了能稳定重现问题的办法,总算给问题的解决打开了一个口子。
首次尝试 #
此时,可以正式的在代码中查找问题的原因了。
来大概说明一下该存储服务的架构:
- 主线程负责接收客户端请求,并且进行解析。
- 如果是读请求,将分派给读请求处理线程,由这个线程与存储引擎库进行交互,查询数据。此时该线程数量配置为2。
- 存储引擎库负责存储落地到磁盘的数据,类似leveldb,只不过这部分是我们自己写的存储引擎。
- 在读线程从存储引擎中查询数据返回后,将把数据返回给主线程,由主线程负责应答客户端。
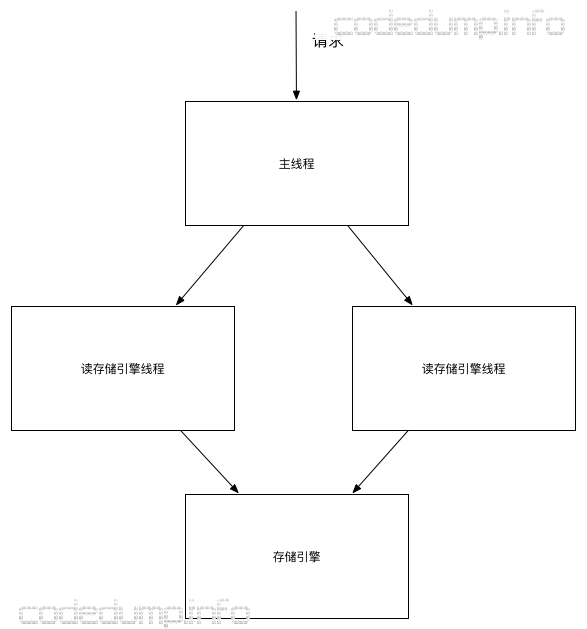
在这几步中,第1和第4步是在主线程中进行的,第2和第3步是在读存储引擎线程中进行的。在这个过程中,如果同一个客户端有多个读请求,那么只有按照这四步在处理完毕一个读请求之后,才会继续从该客户端中取出下一个请求进行处理。
在几次重现问题的过程中,发现出错的都是在第2步和第4步中,该请求客户端的数据结构某些成员出现了错乱,即要访问的指针地址已经无效了,导致的错误。
指针无效,一般来说有两种可能性:
- 被无效地址覆盖了这个指针。
- 指针已经被释放的情况下继续使用。
当时尝试把一些错误的指针地址打印出来,发现有几次都是是字符串“pcm*”的16进制表示,当时在想这个特殊的字符串到底是什么,百思不得其解的时候,一位曾经使用过mcperf工具的同事,想起来mcperf做压测时的key就是"mcp"开头的,而因为是小端方式,所以如果使用这个类型的字符串,去覆盖指针,那么就变成了"pcm"。我们很快验证了这个说法,mcperf确实是以这个为前缀来写入数据的。
此时,猜测问题的原因在于:当读存储引擎线程去访问存储引擎时,某些错误导致从存储引擎读出来的数据,将客户端请求数据写乱,从而导致了崩溃。
由于同时有两个读存储引擎的线程,猜测这里是不是因为多线程访问出了问题,导致的错误呢?
为了验证这个问题,最简单的办法就是将线程数量改成1,重新用mcperf试了几次,确实没有再次出现问题。此时已经是周五,我们缓了一口气,打算以此修改暂时上测试环境利用周末的时间观察一下情况。
柳暗花明 #
前面提到过,猜测问题出现的原因,是多线程访问存储引擎时将某个数据写错乱了,导致其中的指针无效。
clang和gcc 4.8有对应的编译参数,可以用来检测内存错误的写操作,即Address Sanitizer工具。为了兼容线上比较老的系统,之前我们的服务都是在gcc 4.1的环境下进行编译的,为了使用这个工具,首先需要折腾到满足gcc版本号大于4.8的系统上进行编译。
然而,在折腾编译并且运行后,同样使用mcperf的情况下,并不能看到有内存错误覆盖写的提示,我尝试了多次都没有看到。难道是工具没有起作用?
为了验证该工具的作用,我简单在出错代码的前面加入了一段肯定有问题的代码,比如:
char a[100] = {'0'};
a[100] = '1';
而在加入这段有问题的代码之后再次运行,就能看到编译器对这段代码的提示。可见,Address Sanitizer工具是起作用的。那么,前面的过程中没有看到问题,只能说明一个问题:并没有内存错误写的情况发生。
此时想到另一个可能,就是有没有可能是多线程在没有保护的情况下访问了某段数据导致的问题?
gcc同样也有类似的工具来检查这类错误,即Thread Sanitizer工具。然而,在给项目Makefile加入该编译参数后,程序一运行就退出了,根本看不出什么有用的信息来。
此时想到的另一个工具是valgrind。大多数时候,valgrind只是用来做内存泄露检测的,其实它也可以用来做线程数据竞争的检查,使用参数 –tool=helgrind 即可。使用valgrind之后,打印出来疑似有问题的代码如下:
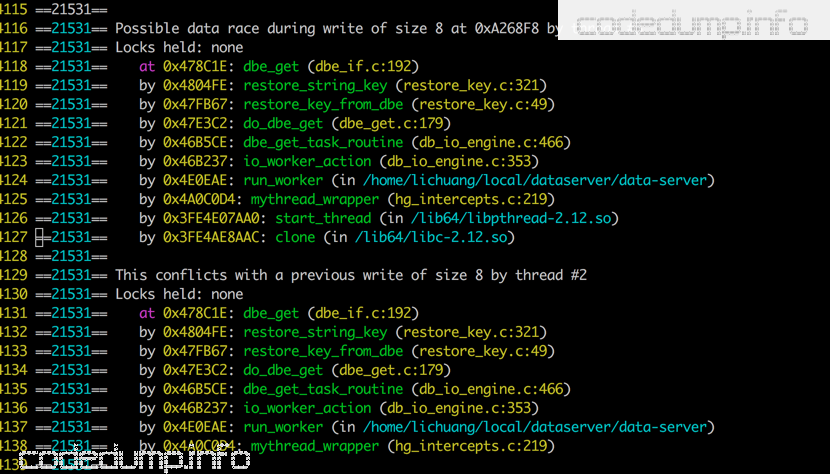
到了这里,猜测问题的原因就是由于多线程访问数据导致的错误。
因为有多个处理读请求数据的线程,首先猜测的是不是某些错误的处理,导致了可以在同一时间多个线程都操作该请求客户端的数据。但是通过review代码,发现这部分处理是没有问题的,另外在访问存储引擎查询数据时,入口处也确实进行了加锁的操作。
为了验证我的观点,我在每个请求客户端结构体中,新增了一个数据用于保存线程id,这个线程id在进入读线程中设置,而从读线程处理完毕转发给主线程之前重置为0。有了这个数据,在每次请求从主线程进入读线程中,都会判断一下这个值是不是非0,如果有非0的值那么说明此时有另外的读线程在进行处理。然而也并没有看到有异常的情况出现。
所以,这一步的猜测,即猜测是由于多线程操作客户端数据导致的问题,看起来方向是错误的了。而之前在测试环境上修改了读线程数为1的版本,也出现了崩溃。所以,问题的原因并不是由多个读线程导致的。
终见曙光 #
前面提到过,目前能确定的是,与客户端连接相关的指针无效了,而一个指针无效,一般来说是两种可能:
- 被无效地址覆盖了这个指针。
- 指针已经被释放的情况下继续使用。
既然前面验证了第一个方向,不存在多线程覆盖该指针数据导致无效的情况,那么接下来就看看是否存在已经释放的情况下继续使用指针而导致了问题。
为了查找释放该指针的情况,首先我找到完成这个释放操作的函数,查找所有可能调用该函数的地方。发现有十几处,每一处都看有点繁琐,为了辅助调试,修改了函数的实现,新增传入一个int型参数,每个调用者传入不同的参数以此来区分不同的调用者,同时在函数内将被释放的指针以及传入的参数都打印出来。
释放时的日志中有了指针,就可以与core的情况下与出错时的指针做对比,知道是哪个指针出的问题;而有了每个调用者传入的参数,又可以定位到这个出错的指针在释放时是被哪里调用了。
加上调试信息之后,又跑了几次都在同一个地方调用,我又重新review了一下这部分的代码逻辑,终于定位到了问题真实的原因。
一个连接,可能会一次性的从同一个客户端接收到多个请求,即所谓的“pipeline”方式:客户端在上一次请求还没有应答的情况下,继续往这个链接中发生请求数据。
而主线程的处理逻辑大体是这样的:
while true:
如果客户端可写:
应答客户端请求
如果应答失败:
关闭客户端连接
如果客户端有未处理的请求:
读客户端的请求数据进行处理
这里的问题的时间序列大概是这样的,假设当前一个链接同时存在A、B两个请求:
- 主线程已经处理了A请求,但是因为此时客户端还不可写,因此没有应答客户端,继续处理下一个B请求,将请求数据放到辅助线程中进行处理。
- epoll通知客户端可写,主线程应答A请求的回复给客户端,但是应答出错,那么就会关闭这个连接。这种通知可写,又写失败的请求,大多发生在客户端关闭了连接时。
- 此时从辅助线程处理的B请求已经处理完毕了,辅助线程将处理结果告知主线程,主线程准备做下一步的处理时,第二步中已经关闭了连接,于是出错了。
这个问题出现的临界条件是:请求并发量大,同时应用采用了使用pipeline方式的客户端,而在某些极端的情况下,比如同一个客户端已经堆积了很多请求在服务器的pipeline队列中,此时服务器处理应答也慢,导致客户度超时关闭了连接,而服务器主线程如果在这种情况下继续处理堆积的请求,就可能访问已经释放的连接对象导致出错。
总结 #
- 找到能稳定重现问题的办法很重要。一般来说,首先应该思考,同一个服务在别的业务下面没有出现问题,在另一个业务上出现了问题,那么以存储类服务来看,首先应该考虑环境以及数据有什么区别,从这里找突破口来重现问题。
- 需要熟悉使用各种工具。以C系列的服务器来说,出现问题大部分就是指针无效、内存泄露等,针对这些常用的工具就是Address Sanitizer、 valgrind等。
- 大胆假设、小心求证。跟进这种复杂的bug时,最好不要在一旁呆着空想,因为经常疑难的问题是在某些临界条件下出现的,就是同一段代码正常情况下是没有问题的,这些临界条件才触发的问题。因此,有很多看上去觉得没问题的地方,在临界条件下就成了问题。此时空想是解决不了问题的,需要动手来做一些实验、加一些调试代码和日志等,来验证你的猜测对不对。常见的临界条件有:线程调度导致的错误,由于操作系统内核调度线程对应用程序而言不可知,即同样的代码,先调度线程A执行再调度线程B执行,和反之的情况有截然不同的效果;另外数据也有可能导致不同的临界条件,这个需要具体看不同的业务数据都有哪些特点来具体分析。