本文是《面向应用开发者的系统指南》文档其中的一篇,完整的目录见《面向应用开发者的系统指南》导论。
概论 #
进程即处于执行状态的程序。操作系统执行进程时,大体经历了以下步骤:
- 为进程分配空间及其他相关资源。
- 加载进程可执行程序到内存中。
- 由调度器选择进程来占用CPU资源执行。
从上面的描述可以看到,进程并不是仅仅只有可执行程序二进制文件就可以运行起来,还需要执行时所需要的资源(内存、CPU等)、进程执行时需要的其他共享库等。
在现代操作系统中,进程提供了针对两种资源的虚拟机制:
- 虚拟处理器。
- 虚拟内存。
虽然在同一时间有多个进程在执行,即分享处理器资源,但是虚拟处理器提供了一种假象:让这些进程认为自己都在独占处理器执行,这里涉及到进程调度部分的内容,在后面进程调度篇再展开讨论。
同时,进程使用的内存实际上虚拟内存,虚拟内存机制使进程以为自己拥有整个4G空间(32位处理器下)而不必关心其他进程的内存空间,这部分内容在内存篇中讲解。
程序本身并不是进程,进程是在执行的程序以及相关资源的总称。
本篇从进程开始讲起,涉及内核管理进程的数据结构、与进程创建和执行相关的系统调用、进程的状态。
数据结构 #
Linux内核使用task_struct结构体来描述一个进程的所有信息。考虑这个结构体的内容太多,这里并不打算全部列举出来,到讲解需要涉及到的时候才提出其中的某些成员详细说明,这里只列出最关键的几个成员:
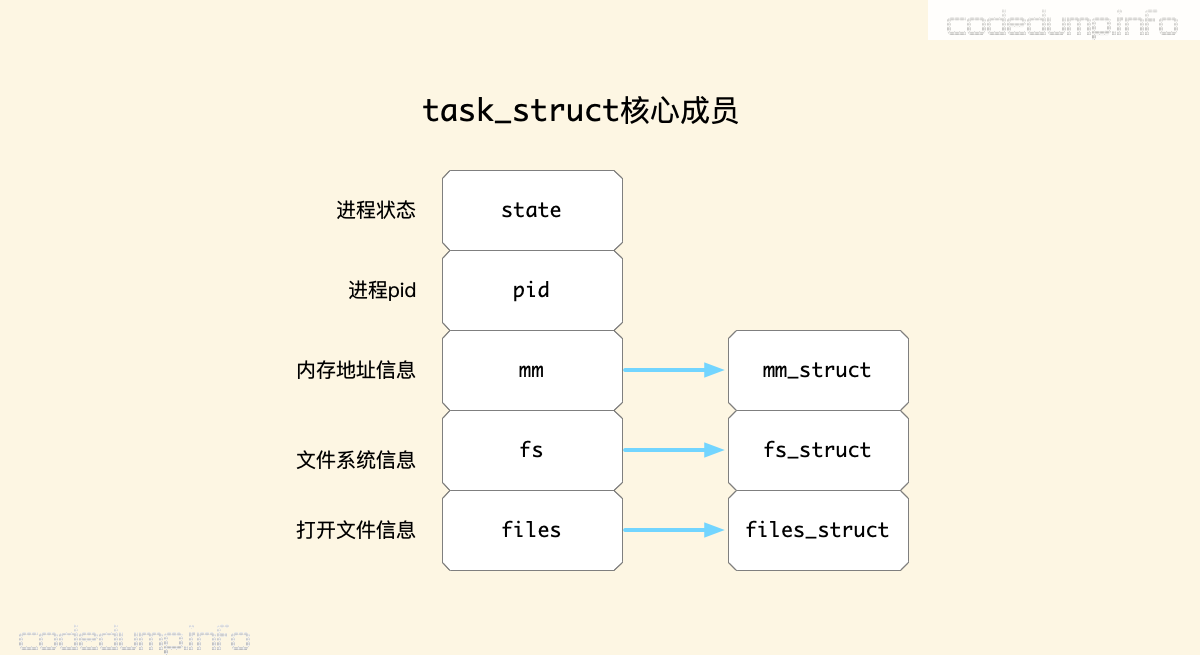
其中:
- state:用于表示进程的状态,下面将展开讨论。
- pid:每个进程都有一个pid与之对应。
- mm:类型为
mm_struct,用于表示进程的内存地址信息,后面内存部分将展开讨论。 - fs:类型为
fs_struct,用于表示文件系统信息,后面IO部分将展开讨论。 - files:类型为
files_struct,用于表示进程打开文件的信息,后面IO部分将展开讨论。
进程的状态 #
task_struct中的state成员,用于表示当前进程的状态,进程的状态必然处于以下五种状态之一:
- TASK_RUNNING:进程是可执行的(Runnable),表示进程要么正在执行,要么正要准备执行(已经就绪),等待cpu时间片的调度。
- TASK_INTERRUPTIBLE:进程因为等待一些条件而被挂起(阻塞)而所处的状态。这些条件主要包括:硬中断、资源、一些信号等,一旦等待的条件成立,进程就会从该状态(阻塞)迅速转化成为就绪状态TASK_RUNNING。
- TASK_UNINTERRUPTIBLE:此进程状态类似于
TASK_INTERRUPTIBLE,只是它不会处理信号。中断处于这种状态的进程是不合适的,因为它可能正在完成某些重要的任务。 当它所等待的事件发生时,进程将被显式的唤醒呼叫唤醒。 - TASK_TRACED:正被调试程序等其它进程监控时,进程将进入这种状态。
- TASK_STOPPED:进程被停止执行,当进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后就会进入该状态。
这几个状态之间,转换关系如下图所示:
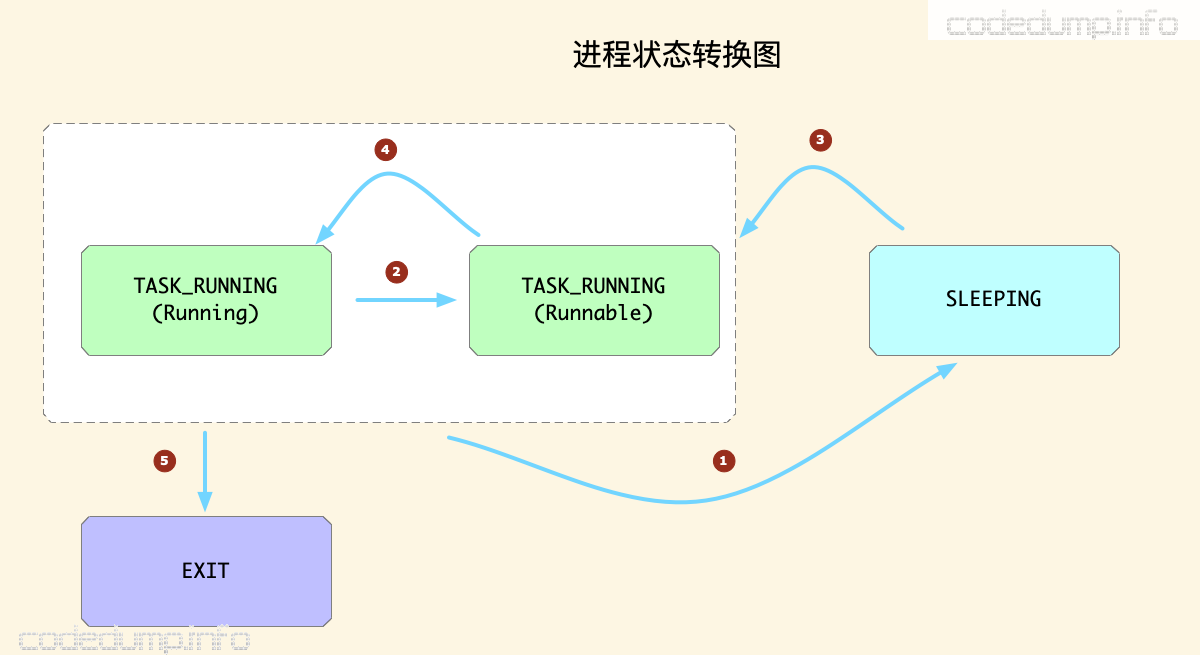
上面的状态转换图中,休眠状态(SLEEPING)包括了TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE,并没有做区分;另外,按照前面的讲述,TASK_RUNNING状态区分了就绪以及在运行状态,由于这两者都是TASK_RUNNING状态,所以分到了同一组里,又因为需要细化这两者之间的状态,内部也有状态之间的迁移。
根据上面的状态转换图,进程状态的转换有这几种情况:
- 正在运行的进程,由于需要等待某些事件(比如网络IO、磁盘IO等),进入休眠状态。
- 正在运行的进程,由于时间片用完或者被其他更高优先级的进程抢占等因素,虽然还是就绪状态,但是被剥夺了执行权,进入就绪队列等待下一次被唤醒执行。
- 处于休眠状态的进程,由于等待的事件满足被唤醒,进入就绪队列中等待被调度运行。
- 处于就绪队列中的进程,被调度器分配CPU时间调度执行。
- 在运行的进程退出。
除了上面几种状态以外,还有僵尸(zombie)状态(内核使用EXIT_ZOMBIE宏表示),用于表示进程已经不再执行,等待被回收的状态。
在使用ps aux命令时,可以查询到系统中进程所处的状态,与上面描述的内核中进程状态一一对应:
- S:休眠状态(sleeping),对应
TASK_INTERRUPTIBLE。 - R:等待运行(runable)对应
TASK_RUNNING,进程处于运行或就绪状态。 - I:空闲状态(idle)。
- Z:僵尸状态(zombie),对应
EXIT_ZOMBIE。 - T:暂停或跟踪状态(Traced),对应
TASK_TRACED。 - D: 不可中断的睡眠状态,对应
TASK_UNINTERRUPTIBLE。
在这里,需要再次强调的是,进程处于Runnable状态时,并不代表就在执行,而是处于就绪可执行状态,由调度器最终决定进程执行。
进程的创建 #
Unix系统将进程的执行放在两个不同的函数中执行:
- fork:fork函数拷贝父进程来创建一个子进程,fork函数调用后会分别在父子进程中各返回一次,区别在于:父进程中的返回值是所创建的子进程的进程pid,而子进程则是返回0表示创建成功。
- exec函数组:在fork调用返回后,子进程就创建完成了,如果需要运行一个与父进程不同的可执行文件,就通过
exec函数组来完成这个工作。如果不调用exec,那么也就意味着父子进程运行的是同一份可执行文件代码。
其他操作系统,有一些把以上两步合在一个函数中完成,即在同一个函数中既完成子进程的创建,也完成子进程的执行,Unix系统将以上两步分开成两个步骤,为shell执行程序提供了方便,因为shell可以在fork创建进程之后,调用exec来执行程序之前改变子进程的一些行为。比如让shell方便的实现类似重定向(redirect)的功能:
wc test.txt > stat
在上面的脚本中,希望将wc命令的输出结果重定向到文件stat中。shell在fork创建了子进程之后,在exec执行之前,关闭该子进程的标准输出,然后打开文件stat,这样打开的文件就获得了刚刚关闭的标准输出的fd,执行wc命令的子进程结果就写入到了文件stat中。
写时复制机制 #
前面提到过,fork函数为子进程创建一个父进程地址空间的副本,复制属于父进程的页面。然而,考虑到许多子进程在创建之后立即调用系统调用exec函数组来执行另外的程序代码,父进程地址空间的复制可能没有必要。
因此,Linux内核在实现时,使用了写时复制的技术(Copy On Write,简称COW),子进程在刚开始创建时与父进程共享同样的地址空间,仅当子进程要修改父进程地址空间的内容时才创建新的地址空间,从而使父子进程有各自的拷贝。
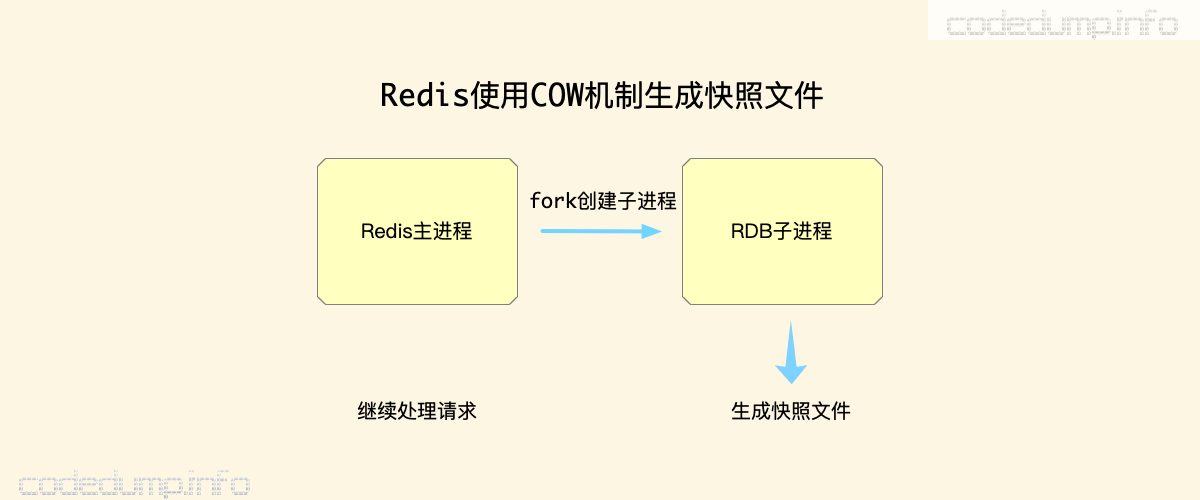
Redis在生成RDB快照文件时,就利用了Linux写时复制机制。生成快照文件时,Redis主进程fork创建一个子进程,根据这里的解释,此时子进程的内存地址就是共享的父进程的空间。这样,父进程可以继续服务请求,而子进程跟进进程创建时候的内存信息,生成快照文件,结束了之后自行退出即可。
fork的实现 #
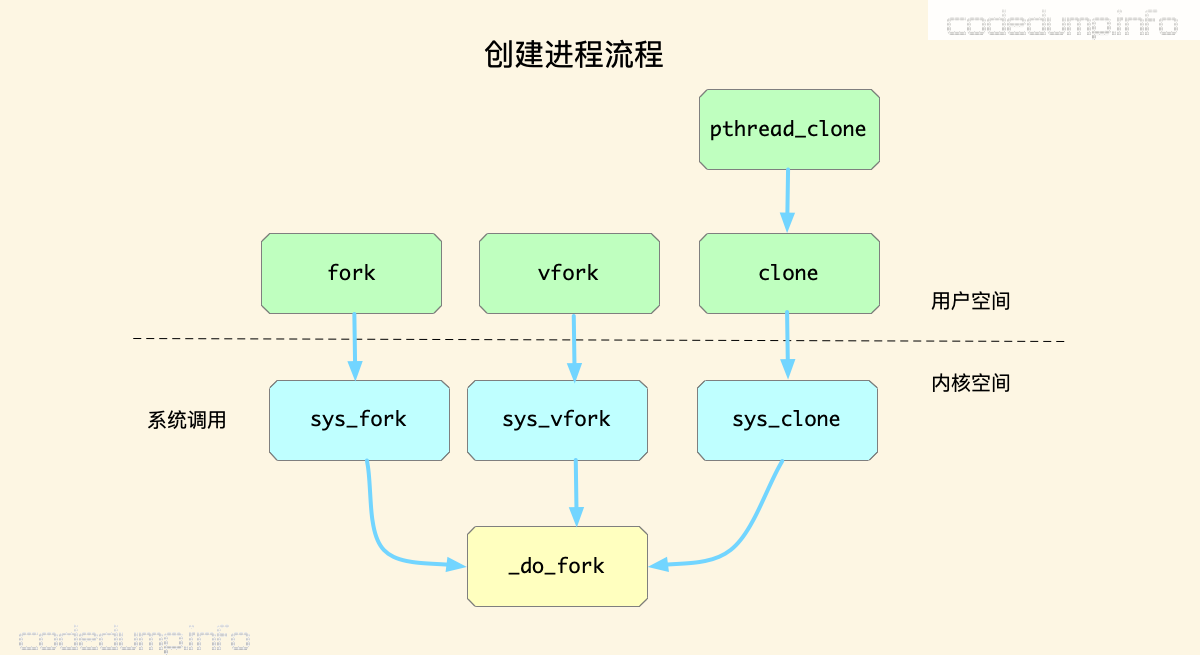
除了fork函数之外,还有另外几个提供给用户态用于创建进程相关的函数。
- vfork:与
fork的区别在于,vfork保证子进程先运行,在它调用exec或exit之后父进程才可能被调度运行。 - clone:
pthread函数族使用clone来创建轻量级进程。
这三个函数,内部实际上最终都调用_do_fork的内核函数完成创建子进程的工作:
下面就展开简单分析_do_fork函数的实现。
_do_fork函数流程 #
创建新进程,调用的是_do_fork函数,其主要流程如下图:
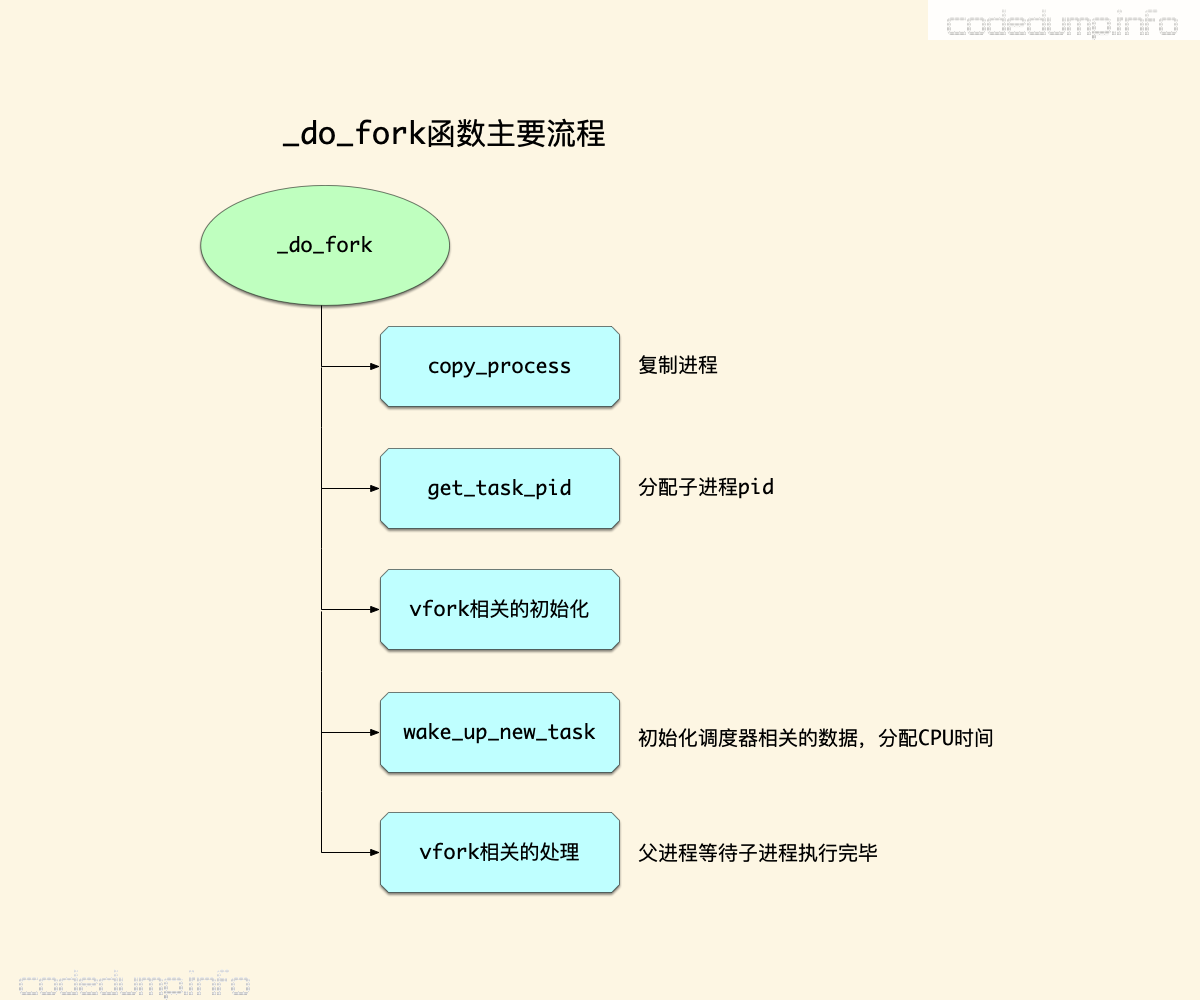
以下就这几个核心流程来做分析。
copy_process #
copy_process函数中完成复制进程数据相关的工作,下面再展开对这个函数的详细分析。
获取子进程pid #
调用get_task_pid函数获得子进程的pid。
vfork相关的初始化处理 #
如果传入的标志位中有CLONE_VFORK标志位,执行相关的初始化,主要是初始化completion结构体。
wake_up_new_task #
wake_up_new_task函数将初始化一些与进程调度器相关的数据,将新创建的子进程加入到调度器的就绪队列中,让子进程有机会被调度器调度执行,同时切换进程状态为TASK_RUNNING:
// kernel/sched/core.c
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, rf.flags);
// 切换进程状态为TASK_RUNNING
p->state = TASK_RUNNING;
// 对调度器运行队列加锁
rq = __task_rq_lock(p, &rf);
// 将进程放入调度器运行队列
activate_task(rq, p, ENQUEUE_NOCLOCK);
// 进程入队列的trace event
trace_sched_wakeup_new(p);
task_rq_unlock(rq, p, &rf);
}
vfork相关的处理 #
如果传入的标志位中有CLONE_VFORK标志位,父进程等待子进程执行exec函数来替换地址空间。在这里,会用到前面初始化的completion结构体,用于父进程等待子进程执行完毕。
copy_process函数的流程 #
copy_process函数负责在创建子进程时拷贝父进程的相关信息,即创建好子进程的task_struct结构体,其主要流程如下图所示:
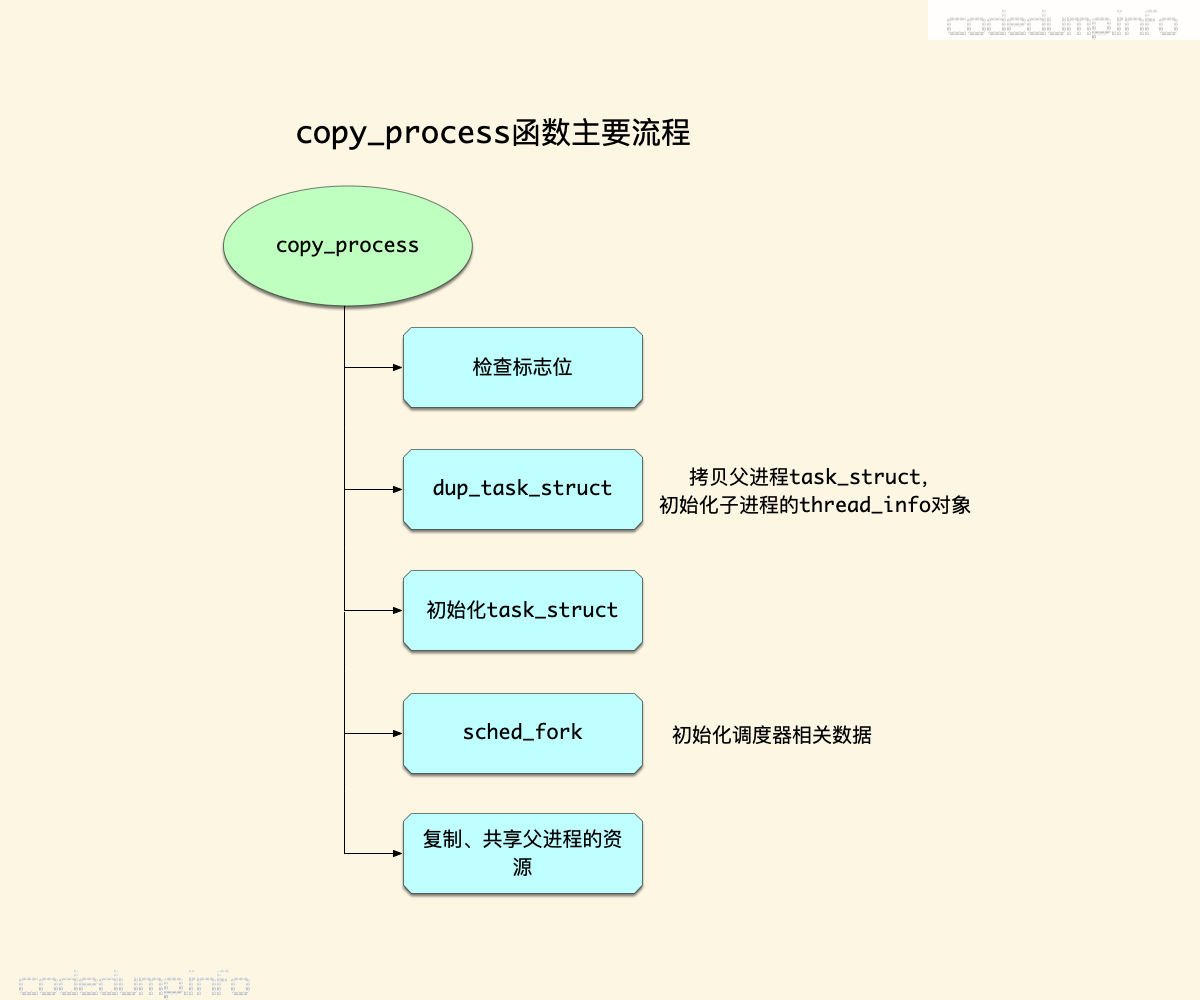
- 调用函数dup_task_struct,复制父进程的task_struct结构体信息。此时,子进程与父进程的描述符是完全相同的。
- 初始化task_struct结构体信息。
- 调用sched_fork函数,设置调度器相关信息。
- 调用copy_*函数,复制、共享父进程的数据,如mm、fs等。
sched_fork #
sched_fork函数用于初始化子进程与调度器相关的信息:
// kernel/sched/core.c
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
// 分配进程执行的cpu
int cpu = get_cpu();
// 设置调度器相关的信息
__sched_fork(clone_flags, p);
// 刚创建好的进程,其状态为TASK_NEW
p->state = TASK_NEW;
// 设置进程优先级
p->prio = current->normal_prio;
// 设置进程的cpu信息
__set_task_cpu(p, cpu);
return 0;
}
复制/共享父进程资源数据 #
task_struct结构体中包含一些表示进程资源的指针,比如mm,files等,创建进程的标志位中有很多名为CLONE_*的标志,表示是从父进程拷贝一份这部分数据,还是与父进程共享一份数据。
- 当这个标志位为0时:说明需要从父进程复制一份该类型资源数据,子进程复制完毕之后,将该资源计数赋值为1,而父进程资源计数维持不变。
- 当这个标志位为1时:说明子进程共享父进程的该类型资源数据,此时该资源计数递增1即可。
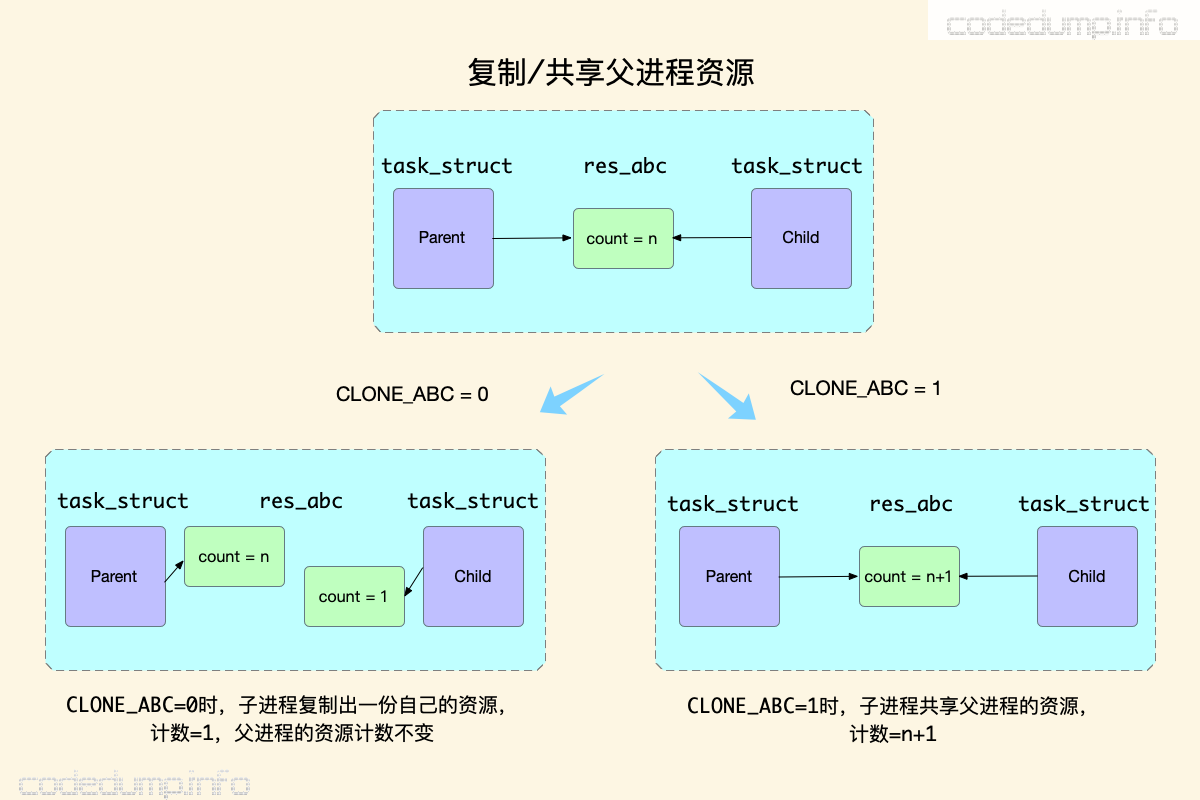
这里调用了如下的copy_*函数完成工作:
copy_semundo函数:如果COPY_SYSVSEM置位,则使用父进程的System V信号量。copy_files函数:如果CLONE_FILES置位,则使用父进程的进程描述符(结构体files_struct),否则调用函数dup_fd复制一份。copy_fs函数:如果CLONE_FS置位,则使用父进程的上下文(结构体fs_struct),否则调用函数copy_fs_struct复制一份。copy_sighand函数:如果CLONE_SIGHAND或者CLONE_THREAD置位,则使用父进程的信号处理程序。copy_signal函数:如果CLONE_THREAD置位,则与父进程使用同一份结构体signal_struct。copy_mm函数:如果CLONE_VM置位,则父子进程共享同一份地址空间,这种情况下父子进程使用同一份mm_struct实例。如果CLONE_VM没有置位,并不意味着子进程需要复制一份父进程的整个地址空间,内核确实会创建页表的一份数据,但是这里还并不复制页表的内容,这是由COW机制决定的,只有在子进程需要修改地址空间内容时才进行实际的复制操作。copy_thread函数:复制进程中特定于线程中的数据。
进程的启动 #
创建完成新进程之后,将使用新进程的代码替换现有代码,即可启动新进程。这一工作由系统调用execve完成,该系统调用的内核入口函数是sys_execve函数,其最终会调用do_execveat_common函数完成工作。
其大体工作流程不外乎以下几步:
- 打开二进制可执行文件。
- 初始化启动时的一些信息,比如命令行参数、环境变量等。
- 调用对应的可执行文件加载函数解析该二进制文件信息,执行进程。
(这里不展开这部分讨论了)
进程的退出 #
如果进程先于其父进程退出,那么它的父进程需要调用wait系统调用等待子进程的退出,进行资源的回收。
没有调用wait回收的子进程,将成为“僵尸进程”,除此之外,还有另一种进程叫“孤儿进程”,下面展开看看这两种进程。
孤儿进程和僵尸进程 #
在Linux系统中,正常情况下,当一个进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
但是这个过程也有以外的情况:
- 孤儿进程:一个父进程先于它的子进程退出,这些子进程将成为
孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。 - 僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。
孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上,当init成为进程的父进程时,内部会循环调用wait函数等待其管辖的子进程的退出,因此孤儿进程并不会有什么危害。
相反,僵尸进程因为一直没有被回收,其占用的进程pid也就一直不会回收,而进程pid属于系统的一个资源,这将导致这个资源的泄露,因此僵尸进程是有害的。如果使用ps aux命令来查看进程状态,那么僵尸进程的状态就是Z。
下面简单演示两种进程的产生。
首先是孤儿进程:
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <unistd.h>
int main()
{
pid_t pid;
pid = fork();
if (pid < 0)
{
perror("fork error:");
exit(1);
}
if (pid == 0) {
printf("I am the child process.\n");
printf("pid: %d\tppid:%d\n",getpid(),getppid());
printf("I will sleep five seconds.\n");
sleep(5);
printf("pid: %d\tppid:%d\n",getpid(),getppid());
printf("child process is exited.\n");
} else {
printf("I am father process.\n");
sleep(1);
printf("father process is exited.\n");
}
return 0;
}
上面的代码中:
- 父进程调用
fork函数创建一个子进程,返回之后马上退出。 - 子进程在
fork调用返回之后打印出自己的父进程pid,此时就是上面的父进程,然后休眠五秒钟等待父进程退出,然后再次打印父进程pid。
在我的机器上输出如下:
I am father process.
I am the child process.
pid: 5938 ppid:5937
I will sleep five seconds.
father process is exited.
pid: 5938 ppid:1
child process is exited.
可以看到,子进程的父进程pid在五秒之后变成1,即init进程。
再来看僵尸进程的产生:
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <stdlib.h>
int main()
{
pid_t pid;
pid = fork();
if (pid < 0)
{
perror("fork error:");
exit(1);
}
else if (pid == 0)
{
printf("I am child process.I am exiting.\n");
exit(0);
}
printf("I am father process.I will sleep two seconds\n");
sleep(2);
system("ps -o pid,ppid,state,tty,command");
printf("father process is exiting.\n");
return 0;
}
上面的代码中:
- 子进程在
fork调用返回之后马上退出。 - 父进程在
fork调用返回之后先休眠2秒等待子进程退出,然后调用system函数打印出ps命令的结果。
输出如下:
I am father process.I will sleep two seconds
I am child process.I am exiting.
PID PPID S TT COMMAND
5817 5816 S pts/19 -zsh
5971 5817 S pts/19 ./t
5972 5971 Z pts/19 [t] <defunct>
5973 5971 S pts/19 sh -c ps -o pid,ppid,state,tty,command
5974 5973 R pts/19 ps -o pid,ppid,state,tty,command
father process is exiting.
可以看到,子进程的状态变成了Z,也就是僵尸进程。
小结 #
总结一下进程这一节涉及到的知识点:
- 进程是在执行的程序以及相关资源的总称。
- Linux内核中使用
task_struct结构体来描述一个进程的所有信息。 - 进程会在不同的状态之间切换,可以使用
ps aux命令来查看进程的状态。 - Linux内核使用
fork函数来创建子进程时,采用的是“写时复制”机制。 fork、vfork、clone函数最终由do_fork函数实现。- Unix系统将创建子进程和执行分开,给shell实现一些特殊的操作提供了方便。