本文是《面向应用开发者的系统指南》文档其中的一篇,完整的目录见《面向应用开发者的系统指南》导论。
概述 #
应用程序需要使用内核提供出来的一些功能,才能完成相应的操作,这个由内核提供出来给用户态程序调用的接口,就是“系统调用(system call)”。比如打开文件时需要调用open系统调用,写文件时需要调用write系统调用,等等。
本节将简单描述Linux在X86下系统调用的工作原理,接着描述如何追踪用户层进程的系统调用。
系统调用原理 #
传统系统调用(Legacy system calls) #
在这里先讨论系统调用的传统实现方式,在这里需要解决以下几个问题:
- 用户态怎么触发系统调用?
- 用户态怎么传递参数给系统调用?
内核预留了一个特殊的软中断号 128 (0x80),用户空间程序使用它可以进入内核执行系统调用,在内核中定义了宏IA32_SYSCALL_VECTOR与之对应:
// arch/x86/include/asm/irq_vectors.h
#define IA32_SYSCALL_VECTOR 0x80
触发给软中断时会调用到汇编编写的函数 entry_INT80_32中:
// arch/x86/kernel/idt.h
SYSG(IA32_SYSCALL_VECTOR, entry_INT80_32),
entry_INT80_32函数在arch/x86/entry/entry_32.S中实现,其最终会走到do_int80_syscall_32函数中调用系统调用。
以上解决了第一个问题,即用户态通过触发软中断int 0x80来调用系统调用的,接下来的问题是,内核如何知道调用的是哪个系统调用,以及怎么解决给系统调用传递参数的问题。
在函数entry_INT80_32的注释中,看到有如下的描述:
// arch/x86/entry/entry_32.S
/*
* Arguments:
* eax system call number
* ebx arg1
* ecx arg2
* edx arg3
* esi arg4
* edi arg5
* ebp arg6
*/
可见,寄存器eax中存放的是系统调用编号,接下来的几个寄存器分别存放传递进来的参数。
于是上面的两个疑问也解决了。
内核中使用一个数组,来具体保存具体系统调用编号与其实现函数的对应关系,该数组名称为ia32_sys_call_table,因此在最后一步调用系统调用时,代码是这样的:
// arch/x86/entry/common.c
static __always_inline void do_syscall_32_irqs_on(struct pt_regs *regs)
{
// ...
regs->ax = ia32_sys_call_table[nr](
(unsigned int)regs->bx, (unsigned int)regs->cx,
(unsigned int)regs->dx, (unsigned int)regs->si,
(unsigned int)regs->di, (unsigned int)regs->bp);
}
}
而数组ia32_sys_call_table的定义如下:
// arch/x86/syscall_32.c
__visible const sys_call_ptr_t ia32_sys_call_table[__NR_syscall_compat_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_compat_max] = &sys_ni_syscall,
#include <asm/syscalls_32.h>
};
可见,会以sys_ni_syscall的值来初始化数组ia32_sys_call_table,sys_ni_syscall是由汇编定义的一个大数组,内部就是各种系统调用对应的处理函数,在此不再列出。
把以上流程大体总结如下图:
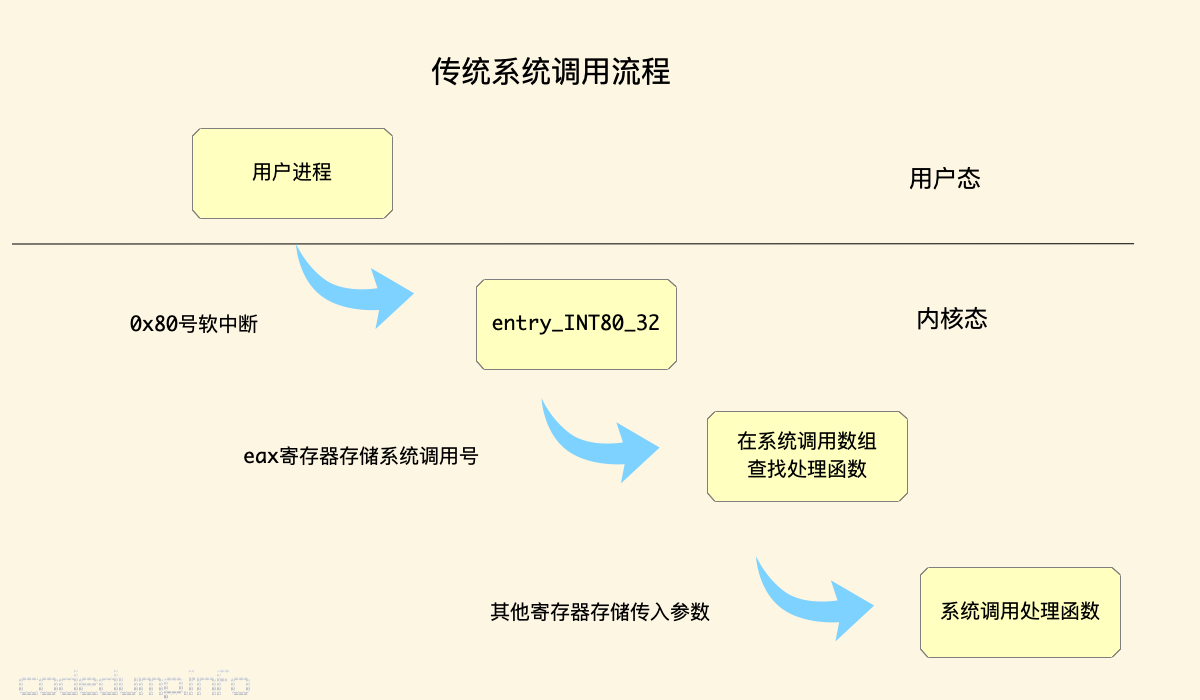
即:
- 通过0x80(128)号软中断触发系统调用。
- 触发系统调用时,
eax寄存器存储了系统调用编号,而其余的几个寄存器存储了传入系统调用的参数。 - 内核使用一个大的系统调用数组来存储系统调用编号与其处理函数的对应关系。
写一个简单的程序来演示一下上面这个调用系统调用的流程:
int
main(int argc, char *argv[])
{
unsigned int syscall_nr = 1;
int exit_status = 42;
asm ("movl %0, %%eax\n" // 编号为0的系统调用是exit
"movl %1, %%ebx\n" // 传入ebx寄存器的参数输入的参数1
"int $0x80" // 触发软中断0x80
"m" (syscall_nr), "m" (exit_status) // 输出参数,其中$0即syscall_nr表示输入参数的数量,$1表示传入系统调用的参数
: /* registers that we are "clobbering", unneeded since we are calling exit */
"eax", "ebx");
}
在这里,编号为0的系统调用是exit,传入给它的参数是42,因此执行之后的结果如下:
$ gcc -o test test.c
$ ./test
$ echo $?
42
快速系统调用 #
以上是传统的系统调用实现,由于源头使用的是软中断,所以其效率并不高。为了加速系统调用的速度,Intel CPU又提供了专门给系统调用使用的指令,称为“快速系统调用(Fast System Call)指令”,分别都包含了进入内核和离开内核的指令:
- 在 32bit 系统上,使用 sysenter 和 sysexit
- 在 64bit 系统上,使用 syscall 和 sysret
在这里,并不打算讨论这些指令的原理,唯一需要说明的是,前面通过软中断触发系统调用时,使用的寄存器在这种情况并不适用,以64位系统来说,其分别使用以下寄存器:
- %rax:存储系统调用编号。
- %rdi、%rsi、%rdx、%r10、%r8、%r9:依次存储传入系统调用的参数。
因此,前面的演示代码如果换用了快速系统调用指令可以修改如下:
int
main(int argc, char *argv[])
{
unsigned long syscall_nr = 60;
long exit_status = 42;
asm ("movq %0, %%rax\n"
"movq %1, %%rdi\n"
"syscall"
: /* output parameters, we aren't outputting anything, no none */
/* (none) */
: /* input parameters mapped to %0 and %1, repsectively */
"m" (syscall_nr), "m" (exit_status)
: /* registers that we are "clobbering", unneeded since we are calling exit */
"rax", "rdi");
}
输出结果同上面一样。
现实中的系统调用 #
以上简述了系统调用的实现原理,然后现实代码中,绝大部分时候,是通过glibc这样的C库来封装系统调用的。
C语言标准中定义了一系列标准函数,只要支持C语言标准的编译器都应该实现这些函数,而glibc这样的库负责封装C标准库函数,转换为对应的系统调用。
以C库中的标准函数fwrite为例来说明,其流程图大体如下:
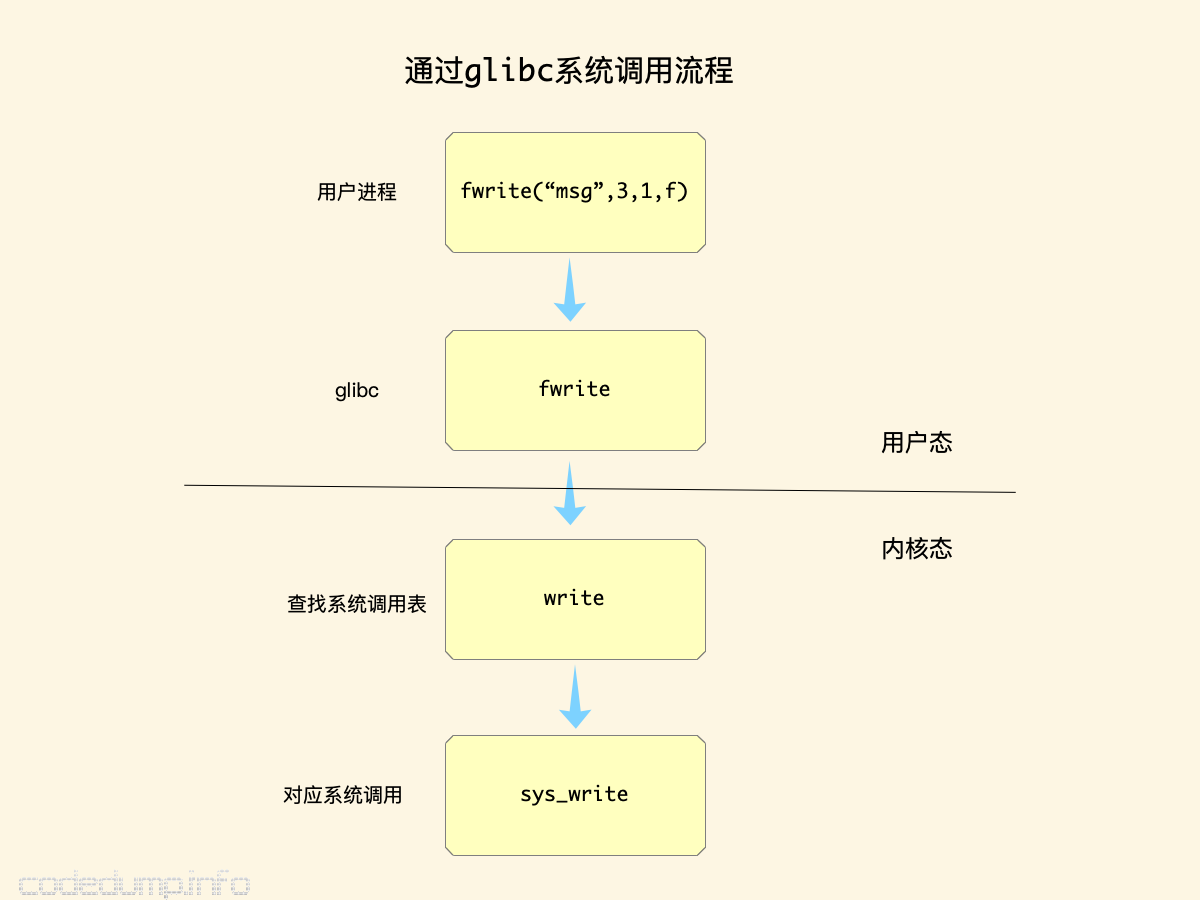
引入glibc这样的中间层有以下几个好处:
- C标准库是一套独立于具体平台的标准,不同的系统虽然内部实现不同,但是只要声称是支持C标准的编译器其都应该实现这些标准的库函数,
glibc的存在屏蔽了各个平台具体内部的实现,使用者只需要调用这些标准C函数即可,不需要关心各个系统的实现。 glibc能够优化用户进程系统调用的次数和频率,以上面的fwrite来说,并不是每一次fwrite都马上会转换成一次write系统调用,glibc库会将这些写操作进行缓存再一次性调用系统调用写入以达到减少系统调用的目的。
另外,以上的两个演示程序中,都是使用的在C代码中嵌入汇编的方式来调用系统调用,而实际上Linux已经提供了调用一个系统调用的函数,可以man 2 syscall看看如何使用,这里不再阐述。
追踪系统调用 #
由于系统调用会进入内核态,其中会涉及到用户态数据参数的传入、用户态切换到内核态等操作,所以系统调用是常见的系统杀手之一。常见的跟踪一个进程都调用了哪些系统调用的方式,可以使用strace命令来完成,比如:
$ strace cat /dev/null
execve("/bin/cat", ["cat", "/dev/null"], [/* 37 vars */]) = 0
brk(NULL) = 0x1c55000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
然而,strace只有系统调用的名称,没有耗时、统计等功能,在这里接下来会演示一些与系统调用相关的systemtap脚本的使用。
查询系统调用 #
系统调用都以syscall为前缀,因此可以这样查询系统调用,需要过滤则搭配grep命令即可,比如想查询系统调用open:
$ sudo stap -L 'syscall.*' | grep open
syscall.mq_open name:string name_uaddr:long filename:string u_attr_uaddr:long oflag:long oflag_str:string mode:long argstr:string $u_name:long int $oflag:long int $mode:long int $u_attr:long int
syscall.open filename:string mode:long __nr:long name:string flags:long flags_str:string argstr:string $filename:long int $flags:long int $mode:long int
syscall.open_by_handle_at name:string mount_dfd:long mount_dfd_str:string handle_uaddr:long flags:long flags_str:string argstr:string $mountdirfd:long int $handle:long int $flags:long int
syscall.openat name:string dfd:long dfd_str:string filename:string flags:long flags_str:string mode:long argstr:string $dfd:long int $filename:long int $flags:long int $mode:long int
syscall.perf_event_open name:string attr_uaddr:long pid:long cpu:long group_fd:long flags:long flags_str:string argstr:string $attr_uptr:long int $pid:long int $cpu:long int $group_fd:long int $flags:long int $ret:long int
当然,如果只是查询系统上的系统调用,实际上并不需要祭出systemtap这把牛刀,这里只是做一个简单的演示。
查询系统调用的时长 #
Systemtap脚本中,在.return后缀里,可以通过使用@entry操作符,在函数被调用的时候存储一个值,比如存储进入这个系统调用时的时间,然后在这里再进行计算。因此可以这样打印出进程调用了某个系统调用的耗时:
// syscall-time.stp
probe syscall.$1.return {
if (target() != 0 && target() != pid()) next
time = gettimeofday_us()-@entry(gettimeofday_us())
printf("[%s:%d] syscall.%s time: %d\n", execname(), pid(), @1, time)
}
使用:
sudo stap syscall-time.stp open -x 15055
[top:15055] syscall.open time: 3
[top:15055] syscall.open time: 2
[top:15055] syscall.open time: 2
[top:15055] syscall.open time: 2
[top:15055] syscall.open time: 3
[top:15055] syscall.open time: 3
该脚本中,传入要追踪的系统调用名称(本例中是open),以及要监控的进程pid,输出该进程中每次调用这个系统调用耗费的时间。
另外,其实systemtap的tapset中已经封装了对任何系统调用的probe事件:
// tapset/linux/syscall_any.stp
probe syscall_any = kernel.trace("sys_enter")
{
__set_syscall_pt_regs($regs)
syscall_nr = $id
name = syscall_name($id)
}
在这里,syscall_any在内核的trace事件sys_enter中被触发,变量syscall_nr存储了系统调用编号,而name存储了系统调用名称。因此如果要跟进任何的系统调用,可以类似下面的脚本这么来:
probe syscall_any {
entry_time[tid()] = gettimeofday_ns();
sys[tid()] = syscall_nr
}
probe syscall_any.return {
et = entry_time[tid()]
id = sys[tid()]
delete entry_time[tid()]
delete sys[tid()]
if (et)
arr[pid(), id] += (gettimeofday_ns() - et)
}
查询占用时间最长的系统调用 #
既然可以拿到每个系统调用的时间,就可以使用systemtap中的统计函数对调用的系统调用进行统计,定时输出统计结果,如下所示:
# syscall-count.stp
global follow_fork = 0
global thread_time
global time_count
global syscalls_nonreturn[2]
probe begin
{
/* list those syscalls that never .return */
syscalls_nonreturn["exit"]=1
syscalls_nonreturn["exit_group"]=1
}
function filter_p()
{
if (target() == 0) return 0; /* system-wide */
if (!follow_fork && pid() != target()) return 1; /* single-process */
if (follow_fork && !target_set_pid(pid())) return 1; /* multi-process */
return 0;
}
# 任何一次系统调用
probe nd_syscall.*
{
if (filter_p()) next;
thread_time[execname(),pid(),name]=gettimeofday_us()
}
# 任何一次系统调用返回
probe nd_syscall.*.return
{
if (filter_p()) next;
if (name in syscalls_nonreturn) next
s = thread_time[execname(),pid(),name]
if (s!=0) {
time_count[execname(),pid(),name] <<< gettimeofday_us() - s
delete thread_time[execname(),pid(),name]
}
}
probe timer.s(1) {
printf("[exe:pid]syscall time:count\n\n")
foreach ([exe,pid,name] in time_count- limit 10)
printf("[%s:%d]%s %d:%d\n", exe,pid,name, @sum(time_count[exe, pid,name]), @count(time_count[exe, pid,name]))
delete time_count
}
输出举例:
$ sudo stap syscall-count.stp -x 2449 -T 2 -w
[exe:pid]syscall time:count
[dockerd:2449]futex 504414:18
[dockerd:2449]pselect6 640:10
[dockerd:2449]epoll_wait 500719:6
[dockerd:2449]read 55:4
[dockerd:2449]write 54:2
这个脚本注意以下几点:
- 因为要追踪所有的系统调用,实际耗时是很长的,所以在查询完毕有对应的系统调用之后,再具体看特定的系统调用。
- 有一些系统调用是不会返回的,其作用就是退出进程,比如exit和exit_group,在begin的时候把这两个系统调用记录下来,不针对它们打印时间了。
- 可以根据全局变量follow_fork来控制是否跟踪子进程。
- 在这里没有办法使用前面例子中的@entry操作符,因为它不能用在通配符的探针函数。
打印系统调用的用户调用栈 #
如果已经知道是哪个系统函数的耗时最多,此时就可以具体打印到底是哪些进程调用栈调用了这个系统调用:
# syscall-backtrace.stp
global backtrace
probe syscall.$1.call {
if (target() != 0 && target() != pid()) next
backtrace[execname(), pid(), ubacktrace()] <<< 1
}
probe timer.s(1) {
foreach ([exe,pid,ubt] in backtrace- limit 10) {
printf("[%s:%d]%s %d\n", exe,pid,name, @count(backtrace[exe, pid,ubt]))
print_usyms(ubt);
}
delete backtrace
}
这个脚本当每次调用系统调用时,记录其用户调用栈,然后在定时器中打印出来。
直接打印用户调用栈可能只能得到一串十六进制的地址,此时最好使用print_usyms这个tapset函数,对应的内核调用栈就使用print_syms,当然即便是这样,在没有调试符号信息的情况下也只能输出十六进制地址。
输出示例:
$ sudo stap syscall-backtrace.stp futex -x 2449 -T 2 -w --all-modules
[dockerd:2449] 30
小结 #
在本节中,简单描述了系统调用的实现原理,其传统方式采用软中断实现,这种方式的效率较低,更新的办法使用了CPU提供的专门针对系统调用的指令来实现。绝大部分情况下,用户进程并不会直接使用系统调用来访问内核的资源,而是通过glibc封装好的C语言标准库来完成工作。
strace命令可以打印一个用户进程在运行过程中调用的系统调用,然而这些信息对于跟踪进程和系统的行为还不够,因为没有系统调用相关的统计、耗时等信息,这时候systemtap又发挥了作用,本节的最后介绍了systemtap如何追踪系统及进程系统调用行为的一些脚本示例。