本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系统存储数据使用的KV嵌入式DB,使用Go编码实现,内部是一个B+树结构体。关于etcd、raft协议以及B+树,可以参考之前的文章:
本文的写作,主要参考了《区块的持久化之BoltDB》系列文章以及boltdb 源码分析
在上一节里面,系统的介绍了Boltdb中几种类型页面的格式,有了这些基础,本节开始介绍boltdb中的Bucket结构。
Bucket #
概述 #
在上一节中,Bucket类比于mysql中的table,在boltdb中,meta页面中有一个成员bucket,其存储了整个数据库根bucket的信息,而一个数据库中存储的其他table的信息,则作为子bucket存储到Bucket中。这几个数据结构的关系如下:
type DB struct {
// ...
meta0 *meta
meta1 *meta
}
type meta struct {
// ...
root bucket // 根bucket的信息
}
type Bucket struct {
*bucket
// ...
buckets map[string]*Bucket // 存储子bucket的对应关系
}
type bucket struct {
// 根节点的page id
root pgid // page id of the bucket's root-level page
// 单调递增的序列号
sequence uint64 // monotonically incrementing, used by NextSequence()
}
在bucket数据结构中,两个成员的作用是:
- root:该bucket的根节点的page id。
- sequence:该bucket当前的序列号,单调递增,在函数
NextSequence中使用。
每个Bucket数据结构,都继承自bucket,同时其中的buckets存储了该Bucket中子Bucket名字的对应关系。
最后,meta页面的root成员,存储的就是这个db的根bucket页面信息。这几个数据结构之间的关系如下图:
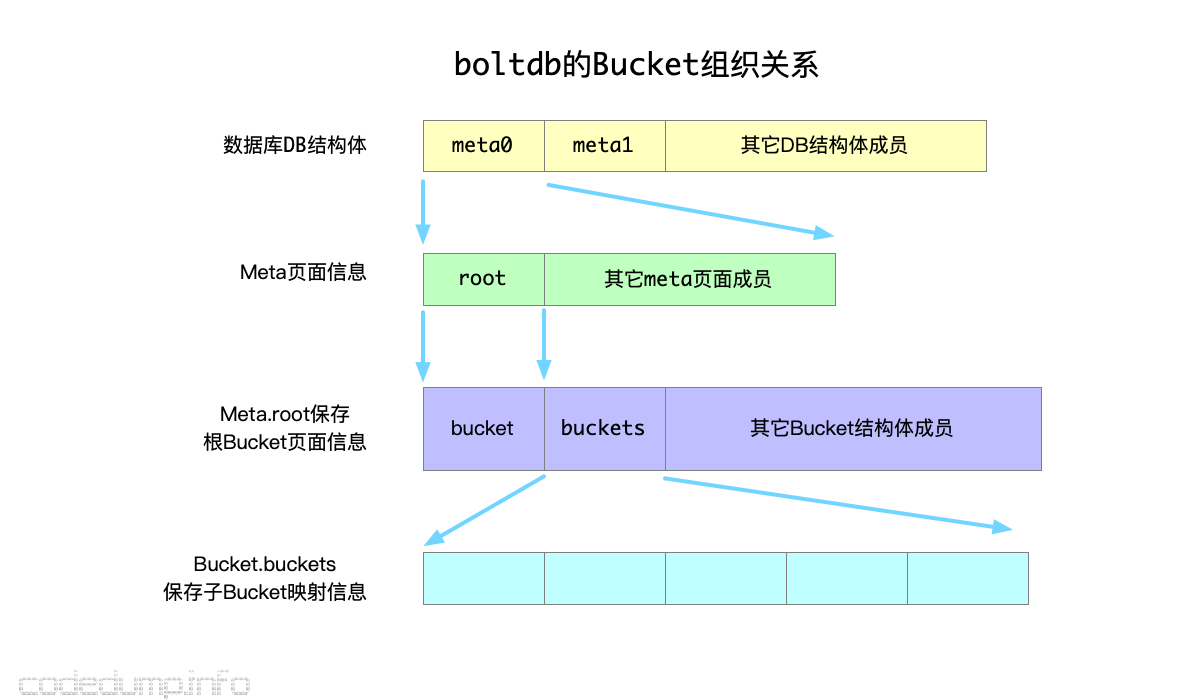
在上图中:
DB结构体是表示整一个boltdb数据库的结构体,其中有meta0和meta1两个meta类型的成员,用于保存meta页面信息。meta页面中,其中的root是一个bucket类型成员,保存了根bucket的页面信息。- 根据
bucket中的页面信息,就能找到DB的根Bucket信息,其中的buckets成员保存了该数据库中所有子bucket名字与实体之间的映射关系。
Bucket结构体定义 #
接下来介绍Bucket结构体成员,其定义如下:
type Bucket struct {
*bucket
tx *Tx // the associated transaction
buckets map[string]*Bucket // subbucket cache
page *page // inline page reference
rootNode *node // materialized node for the root page.
nodes map[pgid]*node // node cache
// Sets the threshold for filling nodes when they split. By default,
// the bucket will fill to 50% but it can be useful to increase this
// amount if you know that your write workloads are mostly append-only.
//
// This is non-persisted across transactions so it must be set in every Tx.
FillPercent float64
}
其中:
- bucket:存储该
Bucket所在页面ID,以及当前序列号。 - tx:当前Bucket关联的事务。
- buckets:前面已经介绍过,维护子
bucket的映射关系。 - page:存储inline页面信息。
- rootNode:该Bucket的B+树根节点指针。
- nodes:缓存已经读入内存的
page对应的node信息。 - FillPercent:这是一个阈值,每个节点的数据量超过该阈值时进行分裂操作,默认值为DefaultFillPercent=0.5。至于B+树分裂操作的流程,可以参考文章最开始的B+树原理链接。
子Bucket #
按照上面的分析,一个bolt的DB存在一个唯一的根Bucket,而DB中不同的table就是该根Bucket的子Bucket,其对应关系存储在Bucket.buckets成员中。那么,子Bucket信息保存在哪里呢?
答案是保存在叶子节点,也就是leafPageElement中,回顾一下这个数据结构的定义:
// leafPageElement represents a node on a leaf page.
type leafPageElement struct {
flags uint32
pos uint32
ksize uint32
vsize uint32
}
其中的flags成员,含义如下:
- 0:表示就是普通的叶子节点。
- 1:表示是子bucket。
即在boltdb中,子Bucket的信息,是做为一种特殊的叶子节点信息存储下来的。boltdb使用了常量来表示这种类型的叶子节点标志位:
const (
bucketLeafFlag = 0x01
)
即:
- 对于一个标志位为0的叶子页面:其内容就是B+树叶子页面的内容,存储的是数据的键值,boltdb中叶子页面的格式示意图在上一节中已经给出。
- 对于一个标志位为1的叶子页面:其内存存储的是Bucket结构体的信息。
有了以上的介绍,理解起来返回一个子Bucket的相关代码就不难了:
func (b *Bucket) Bucket(name []byte) *Bucket {
// Move cursor to key.
// 否则创建一个Cursor查询
c := b.Cursor()
k, v, flags := c.seek(name)
// Return nil if the key doesn't exist or it is not a bucket.
// 查询不到,或者不是子bucket节点,都返回nil
if !bytes.Equal(name, k) || (flags&bucketLeafFlag) == 0 {
return nil
}
// Otherwise create a bucket and cache it.
// 打开这个bucket并且cache到buckets map中
var child = b.openBucket(v)
if b.buckets != nil {
b.buckets[string(name)] = child
}
return child
}
func (b *Bucket) openBucket(value []byte) *Bucket {
// 创建一个bucket
var child = newBucket(b.tx)
// If this is a writable transaction then we need to copy the bucket entry.
// Read-only transactions can point directly at the mmap entry.
if b.tx.writable {
child.bucket = &bucket{}
*child.bucket = *(*bucket)(unsafe.Pointer(&value[0]))
} else {
child.bucket = (*bucket)(unsafe.Pointer(&value[0]))
}
// Save a reference to the inline page if the bucket is inline.
// inline bucket
if child.root == 0 {
// bucket的page
child.page = (*page)(unsafe.Pointer(&value[bucketHeaderSize]))
}
return &child
}
Bucket.Bucket用于根据名字返回一个子Bucket的指针,其流程如下:
- 首先根据子Bucket名字查找到叶子页面的数据、标志位,如果查找失败,说明不存在该子Bucket;或者其标志位不是
bucketLeafFlag,说明这个名字已经被普通数据占用,即:boltdb中不允许子Bucket与其父Bucket中写入的键同名。 - 以上查找成功,就以该叶子页面的数据为参数,调用
Bucket.openBucket函数,根据Bucket结构体格式,反序列化出来Bucket结构体信息返回。
inline page #
从上面的分析可以看到,子Bucket的信息是独占一个叶子页面来存储的,该页面大部分的内容都是冗余的。如果子Bucket中的数据量很少,就会造成磁盘空间的浪费。为了针对这类型Bucket进行优化,boltdb提供了inline page这个特殊的页面,将小的子Bucket数据存放在这里。
这类型的子Bucket需要满足以下两个条件:
- 该子Bucket再没有嵌套的子Bucket了。
- 整个子Bucket的大小不能超过page size/4。
Bucket.inlineable函数就是用来做inline操作的判断的:
// inlineable returns true if a bucket is small enough to be written inline
// and if it contains no subbuckets. Otherwise returns false.
// 返回这个bucket是否能够inline操作
func (b *Bucket) inlineable() bool {
var n = b.rootNode
// Bucket must only contain a single leaf node.
// 如果没有根节点,或者根节点不是叶子节点的不能进行inline操作
if n == nil || !n.isLeaf {
return false
}
// Bucket is not inlineable if it contains subbuckets or if it goes beyond
// our threshold for inline bucket size.
// 有子bucket,或者大小超过maxInlineBucketSize阈值的,都不能进行inline操作
var size = pageHeaderSize
for _, inode := range n.inodes {
size += leafPageElementSize + len(inode.key) + len(inode.value)
if inode.flags&bucketLeafFlag != 0 {
return false
} else if size > b.maxInlineBucketSize() {
return false
}
}
return true
}
// Returns the maximum total size of a bucket to make it a candidate for inlining.
func (b *Bucket) maxInlineBucketSize() int {
return b.tx.db.pageSize / 4
}
Cursor #
以上已经大体了解Bucket的结构,在boltdb查找数据流程中,还是使用了Cursor结构体来做为游标(iterator),保存查找流程中的中间数据,下面也来简单了解一下。
Cursor结构体的定义如下:
type Cursor struct {
bucket *Bucket // 对应的bucket
stack []elemRef // 存储递归遍历时中间过程的栈,由于栈是先进后出结构,所以遍历的过程中层次高的在栈的低端。
}
// 光标移动过程中,中间过程的信息
type elemRef struct {
page *page // 页面
node *node // 内存中的页面信息
index int // 保存在当前page、node遍历到了哪个节点
}
Cursor有以下成员:
- bucket:游标操作所对应的
Bucket指针。 - stack:存储递归遍历过程中的栈,由于栈是先进后出结构,所以遍历的过程中层次高的节点在栈的低端。
每个stack成员类型是elemRef,其成员如下:
- page:页面指针。
- node:内存中的页面信息。
- index:保存遍历到当前页面的索引位置。
由于node是page在内存中的表示,所以实际上在elemRef结构体中,page和node成员同时只会有一个成员不为NULL。
Cursor结构体做为一个迭代器,对外提供的就是常规迭代器所支持的操作:
- First:返回当前Bucket的第一个数据。
- Last:返回当前Bucket的最后一个数据。
- Next:返回当前游标位置的下一个数据。
- Prev:返回当前游标位置的上一个数据。
- Seek:查找到对应的叶子节点返回其键、值。
- keyValue:返回当前游标位置的键、值、标志位。
- Delete:删除当前游标位置的数据。
在这里,不打算讨论其中的所有实现,如果读者对B+树的实现并不了解,可以看最开始介绍B+树原理的连接。
这里以First函数为例简单的讲解其实现,由于B+树是中序遍历的树结构,因此First元素一定是最左边叶子节点的左边第一个元素。带注释的代码实现如下:
// 移动到bucket的第一个元素上,返回其key value数据
func (c *Cursor) First() (key []byte, value []byte) {
_assert(c.bucket.tx.db != nil, "tx closed")
// 修改stack只保存第一个stack,及栈底部
c.stack = c.stack[:0]
// 返回root节点的page、node
p, n := c.bucket.pageNode(c.bucket.root)
// 将root节点所在的page、node信息放到栈顶,index为0,表示从第一个子节点开始遍历
c.stack = append(c.stack, elemRef{page: p, node: n, index: 0})
// 移动到当前的第一个元素
// first函数做的事情:从树顶端开始,从最左边一直往下遍历到叶子节点为止
// 因为B树是中序遍历的,所以最左边的节点数据最小
c.first()
// If we land on an empty page then move to the next value.
// https://github.com/boltdb/bolt/issues/450
// 如果没有元素,就移动到下一个元素
if c.stack[len(c.stack)-1].count() == 0 {
c.next()
}
// 拿到k、v、flags
k, v, flags := c.keyValue()
// 如果是子bucket,就返回k以及nil
if (flags & uint32(bucketLeafFlag)) != 0 {
return k, nil
}
return k, v
}
// first moves the cursor to the first leaf element under the last page in the stack.
// 找到stack最后一个页面中的第一个叶子节点
func (c *Cursor) first() {
for { // 找到最左边第一个叶子节点
// Exit when we hit a leaf page.
// 每次循环取出最后一个元素
var ref = &c.stack[len(c.stack)-1]
if ref.isLeaf() { // 如果是叶子节点就退出循环,即这个循环终止的条件是向下一直找到叶子节点为止
break
}
// Keep adding pages pointing to the first element to the stack.
// 根据ref.index拿到pgid
var pgid pgid
if ref.node != nil {
pgid = ref.node.inodes[ref.index].pgid
} else {
pgid = ref.page.branchPageElement(uint16(ref.index)).pgid
}
// 拿到对应的page、node
p, n := c.bucket.pageNode(pgid)
// 放到栈顶,注意这里的index是0
// 即向下查找的时候取的都是最左边的节点
c.stack = append(c.stack, elemRef{page: p, node: n, index: 0})
}
}